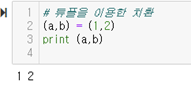
목적
특정 폴더의 파일 이름을 일괄적으로 변경하기.
확장자를 입력하면 해당 확장자 파일을 모두 일련번호나 날짜가 붙은 파일로 변경함.
예를 들어,
dfsafdfa.png --> 0001.png
dagh2113.png --> 0002.png
kdkdkkdk.png ---> 0003.png
혹은
dfsafdfa.png --> 2021-01-23_0001.png
dagh2113.png --> 2021-01-23_0002.png
kdkdkkdk.png ---> 2021-01-23_0003.png
개발 노트
argparse 모듈을 써서 CLI(command line interpreter) 프로그램으로 작성함
progressbar 추가
pathlib으로 확장자 처리
glob으로 현재 경로에서 파일 리스트 추출
타입힌트 기능 사용
설치 및 사용
파이썬의 site-packages에 설치해 python -m 으로 사용합니다.
여러분은 아마 Anaconda를 설치했을 것입니다.
Anaconda Console을 실행하거나 맥 혹은 리눅스 사용자의 경우 터미널을 열어 봅니다.
다음과 같이 실행하여 jupyter console을 실행합니다.
jupyter console

파이썬의 모듈 경로를 확인합니다.
import sys
sys.path

위 깃 허브 링크에서 다운로드 받은 pyrename.py 파일을 site-packages 폴더에 넣습니다.
이제 특정 경로에 저장된 이미지 파일의 이름을 임의로 변경합시다. 콘솔이나 터미널을 열어서 작업합니다.
콘솔에서 디렉토리를 바꾸려면 cd 경로이름 이렇게 합니다.
팁: 윈도의 사용자는 우선 파일 익스플로러 상단의 주소를 ctrl+c로 복사하고 터미널에서 cd 뒤에 커서를 위치시킨 뒤 마우스 우클릭을 합니다. 경로가 바로 붙습니다.
팁: 맥 사용자는 Finder에서 "편집"으로 간 다음 옵션키를 누르면 경로 복사하기가 보입니다.
Dowloads 폴더의 enw 파일 이름을 한 번에 변경해보겠습니다. 터미널을 열어
cd /Users/tagg/Downloads
python -m pyrename --help

--help를 보니 -e 와 -dt 옵션에 관한 설명이 있습니다.
이제 실행 합시다.
python -m pyrename -e enw -dt
enw로 끝나는 확장자를 모두 바꾸고, 날짜 옵션(dt)를 켰습니다.

이상 파이썬 모듈을 설치하여 사용하는 방법을 살펴봤습니다.
CLI 프로그램에 관심이 있는 사람은 깃허브 소스코드를 다운로드 받아 살펴보시면 좋겠네요.












































{kind=link}